风格迁移
前言
图像的风格迁移是一项很有意思的研究,比如把你的自拍变成动漫风格,或者把你拍的风景画转变为梵高的风格,瞬间就高大上了不少。
而另一个问题,则是出于实际工作的需求: 在短视频推荐的时候,我们需要给用户推荐他喜欢的视频的相似视频,又不能完全一样。
而视觉的相似性,在相似视频的判断里起着极大地作用。目前判断相似使用的特征有若干种来源:
- 传统算法的特征
- 分类任务的特征
- 自监督任务的特征
- 行为数据训练的特征
2很好理解,最常见的就是使用ImageNet进行分类训练,然后取其中某层的输出作为特征,进行相似性计算。 但是这样会有一个很明显的问题,ImageNet的分类力度太粗了,很多同一类别的东西在视觉上看起来并不相似, 比如狗,有各种各样品种的狗、全身的、只有头部的等,很难对类内进行更细致的刻画。
而Instance级别的自监督任务则可以部分解决这个问题,这种方法的通常做法是,把每张图片视为一个类别, 同一张图片的不同数据增强,视为正样本;不同图片的数据增强,视为负样本。这样训练得到的特征 可以增加图片之间的区分性,比单纯的分类任务得到的特征要好些。
以din为代表的行为数据训练,则是从另一个角度出发,认为同一个用户的行为序列具有内在的联系,将用户点击过的 内容进行编码,通过avg pool或者attention得到用户特征。在这种方案下,内容特征是一个附属产物,可能比较有效, 但是可解释性上甚至不如前面两者。
2、3的本质都是分类任务,只不过是类别的粒度不同,然而也都是在整张图片这个维度上进行的。 这样会导致一些问题,比如三段式这样的视频,他们的内容不同,但是计算得到的相似度很高,主要原因 就是图片的大部分区域是相同的。要解决这样的问题,可能有很多种方案, 比如去除无意义的区域、只对图片主体进行相似度计算;或者case by case,进行裁剪处理等。
但是这样并为抓住本质问题–相似是有区别的,内容的相似、风格的相似。
内容的相似很好理解,图片的内容是什么,有什么物体等;但是风格相似,就有些不好定义了,是图片的配色?还是纹理?或者是其他的什么东西?
如果说,我们能够显式的给出风格特征和内容特征,是不是可以提供更多维度的相似呢? 比如对下图而言,从左到右依次为图像A,B,C:我们希望,A和C的风格特征是一致的,B和C的内容特征是一致的。
![]()
但是,怎么去做到这点呢?让我们来读一下已有的论文吧。
风格迁移的原理
- 两张图像经过预训练好的分类网络,若提取出的高维特征(high-leval)之间的欧氏距离越小,则这两张图像内容越相似;
- 两张图像经过预训练好的分类网络,若提取出的低维特征(low-level)在数值上基本相等,则这两张图像风格越相似, 换句话说,两张图像相似等价于二者特征Gram的矩阵具有较小的弗罗贝尼乌斯范数。
基于这两点,就可以设计合适的损失函数优化网络。
Image Style Transfer Using Convolutional Neural Networks
这篇论文应该是采用CNN来进行风格迁移的开山之作,基本思想很简单,基于优化方法来进行风格迁移:optimization-based
有原图$\vec{p}$, 风格图片$\vec{a}$, 生成的图片$\vec{x}$,
- 内容相似度: $P^l$ 和 $F^l$ 表示第l层的特征表示,使用MSE loss来表示他们的内容相似度:
- 风格相似度: 参考Texture Synthesis Using Convolutional Neural Networks 这篇文章, 将纹理视为风格,并且使用特征之间的相关作为风格的表达,根据Gram矩阵进行计算。 $G_{ij}^l$表示第l层,feature map i 和 j 表示为向量之后的内积。
第l层提供的loss为
\[E_l = \frac{1}{4N_l^2M_l^2}\sum_{i,j}(G_{ij}^l - A_{ij}^l)^2\] \[L_{style}(\vec{a},\vec{x}) = \sum_{l=0}^Lw_lE_l\]- 在风格和内容之间进行权衡,得到整体loss:
以下两张图片可以更好地帮助理解:
内容重构和风格重构结果
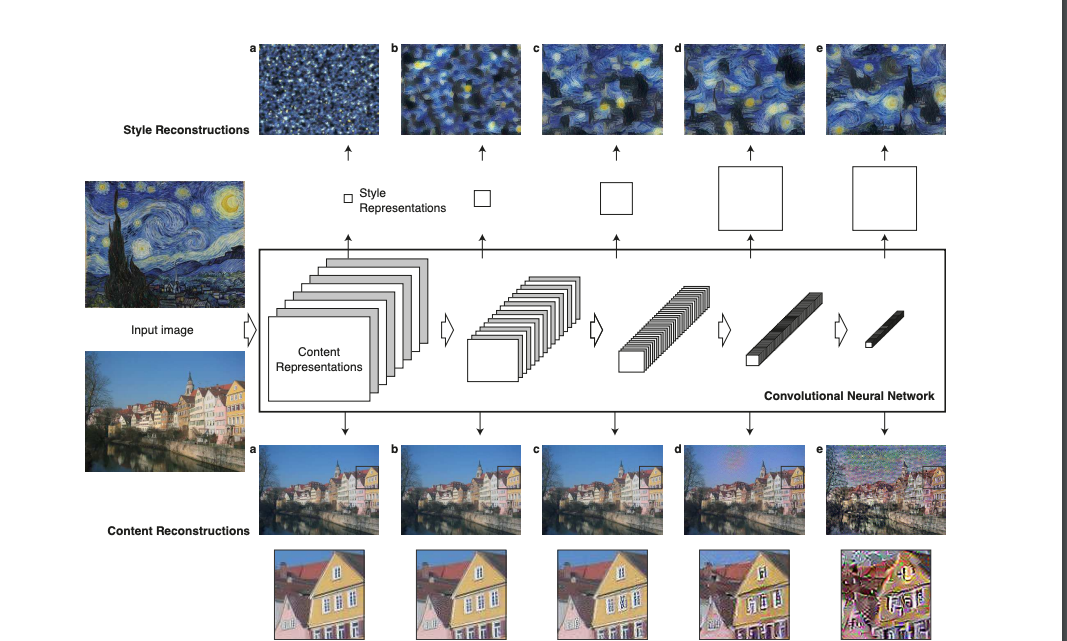
整体训练流程
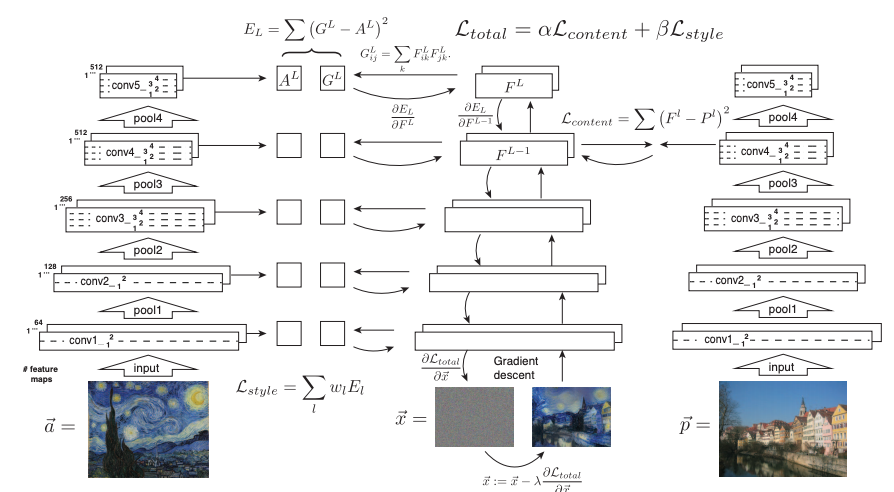
然而,我们很容易发现,由于目标图片是一个优化loss的过程,每次得到结果都要运行很长时间,对大部分人来说是难以接受的。 也就有了一个自然而然的想法,能不能对每种风格,只训练一次呢?然后只输入内容图片,就可以得到目标图片呢? 或者更进一步,能不能任意输入风格图片和内容图片,经过很短时间就可以获取目标图片呢?
方法总是有的,我们来看下下面的这篇论文。
Perceptual Losses for Real-Time Style Transfer and Super-Resolution
与上一篇论文不同,这篇论文通过一个AutoEncoder来拟合风格迁移的过程,相当于把风格记在了网络的权重中, 这样在inference的时候,只需要输入内容图片就可以了。
下图是流程的描述,很容易理解:
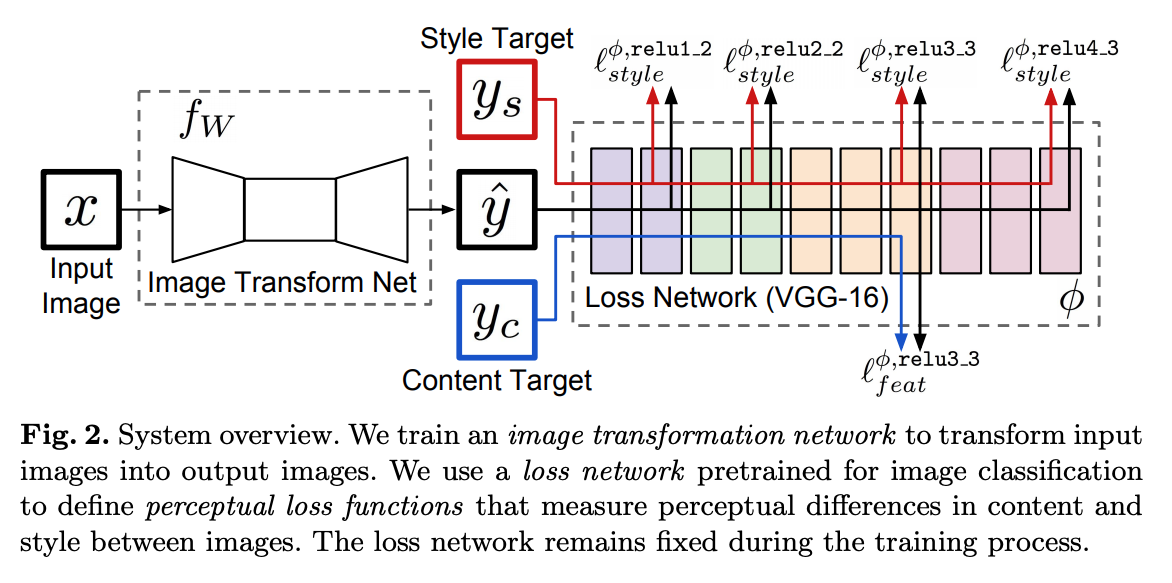
网络由两部分组成,第一部分是AutoEncoder的结构,对输入图片进行变换,得到输出图片; 第二部分是预训练好的VGG网络,用于计算第一步的图片和目标图片的loss;这部分网络的权重是固定的,采用的loss和上篇论文也是一致的。
inference的时候,第一部分输出的结果就是生产的图片。
通过loss的监督,将风格记录在了第一部分网络的权重中,从而减少了optimize的过程,有效加快了风格生成的速度。 然而,似乎哪里不太对……前者可以生产任意风格的图片,但是这篇论文的方法,每个模型只能生产一种风格的图片啊!似乎为了速度,损失了通用性。
有没有一种方法,既可以保持迅速的inference过程,又可以适用任何风格呢?
StyleBank: An Explicit Representation for Neural Image Style Transfer
很暴力的一种方案,既然论文2已经可以将一种风格保存在模型里了,那么我在模型里同时保留多个风格,然后选择用哪个风格来进行迁移,不就完成了吗? 所以这就有StyleBank这篇论文,暴力,但是可用。
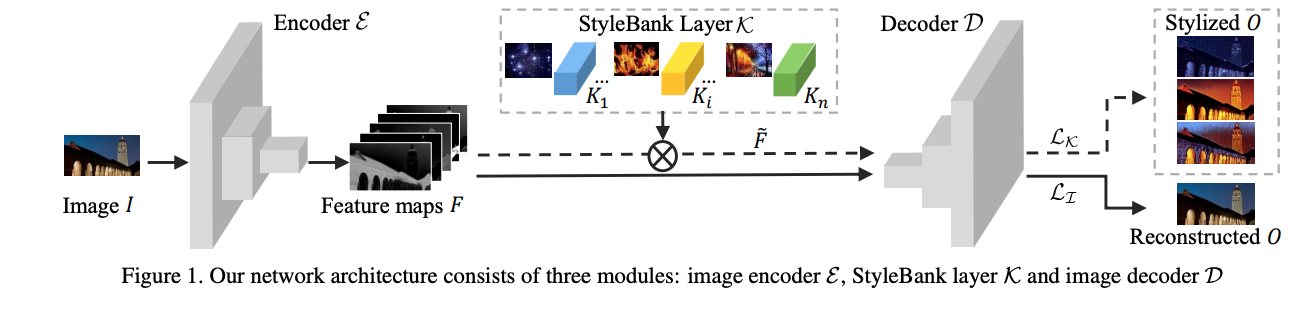
看图也很好理解,模型由三部分组成,Encoder E, StyleBank Layer K, Decoder D, E+D用于内容的重建,而K负责控制不同风格。
这样的设计,有两个好处:
- 增加新的style时可以采用incremental training。锁住E,D,初始化一个新的K进行训练就好,速度很快。
- 可以比较轻松的进行Region-specific style fusion,即将照片不同的区域转化成不同的style。对E输出的feature map F加不同的mask,再与对应的StyleBank layer卷积就好
细节: 训练的时候,训练T次(E+K+D)和1次(E+D)。
stylebank在一定程度上丰富了风格的选择,但是还是做不到任意风格的迁移。
A Learned Representation for Artistic Style
这篇Google的则在之前instance normalization的基础上,提出了conditional instance normalization。 主要思想是,很多不同的艺术风格在有很多相同的视觉元素,这部分没有必要在每个风格里都去计算、保存。 在实验中,作者发现,instance normalizaion中的scale和shift足以表达不同的风格。
\[z = \gamma_s(\frac{x - \mu } {\sigma}) + \beta_s\]IN的公式和BN基本一致,每次normalized后会有一次scale and shift的操作。 而所谓conditional IN,则是不同的style采用不同的scale and shift参数, 也就是图中的$\gamma$和$\beta$ 。 训练过程中每个style分别优化自己的$\gamma$和$\beta$,将feature转换到自己的空间。 而其他层如conv layer,则所有style共用相同的参数。 本质上,即是将每个style投射成一个embedding。(将所有的$\gamma$和$\beta$拼起来,大约有3000维)
这部分想法,相当于使用一个AutoEncoder来对风格进行训练、重塑,只不过直接利用了IN中的scale and shift。
可以发现风格迁移的进化过程很有意思: 1、基于优化的方式,从白噪声出发,直接从内容图片、风格图片优化得到目标图片 2、将内容重构、单个风格作为模型的任务,进行训练优化,单次inference得到目标图片 3、将内容重构、风格模型进行分离,内容部分是一个Encoder-Decoder结构,风格部分保存在另一部分权重里 4、将风格部分也做成一个Encoder-Decoder结构,通过参数控制不同风格;然后进入内容部分的Decoder里
其实,到4这部分,就已经可以满足我们的业务需求了——风格、内容都有了自己对应的embedding,可以用来做些好玩的事情了。如果有很多很多的风格、内容图片进行训练,就可以验证想法对不对了。
但是,单独从风格迁移这个任务来讲的话,又有了一个新的坑——前面的工作最多只能处理32种风格,没有办法处理没见过的风格。怎样才能 处理任意的风格图片呢?
坑都挖好了,肯定是要有人来填的,果不其然,有些工作就开始填坑了:
Exploring the Structure of a Real-time, Arbitrary Neural Artistic Stylization Network)
这篇论文是上一篇的延展,既然每种风格能够用3000维的embedding表示,是不是给定一个网络,能够在inference过程中得到这3000多维向量,就可以了呢?
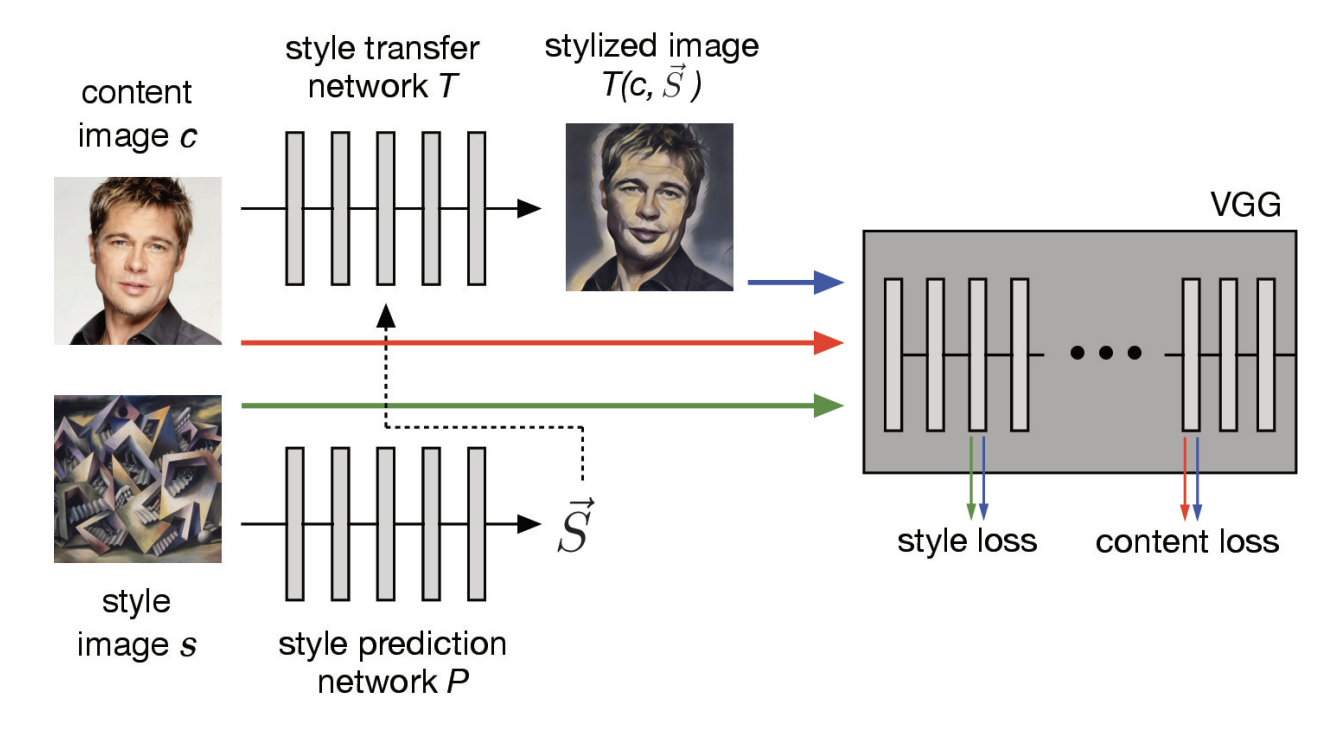
说干就干,他们做了这样一个改变:增加了一个风格预测网络P,预测任意一张风格图片的embedding,也就是上篇论文中的$\gamma$和$\beta$。和上篇论文的主要区别是 embedding的获取方式,上篇论文相当于是一个统计值,类似center_loss中的center,在每次训练中更新并保存下来;而这片论文则是用了一个网络去进行风格的拟合。
这个其实是上节4中提到的,将风格做成了一个完整的Encoder-Decoder结构,但是单独作为一个一篇论文,似乎有些取巧……
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization github
作者认为不同的style其实由feature的variance和mean决定,因此通过将Content image的feature 转换, 使其与style image的feature有相同的variance和mean即可实现风格迁移。
这种方法没有进行风格学习的参数,只要进行如下转换即可:
\[AdaIn(x, y) = \sigma(y)(\frac{(x - \mu (x)}{\sigma(x)}) + \mu (y)\]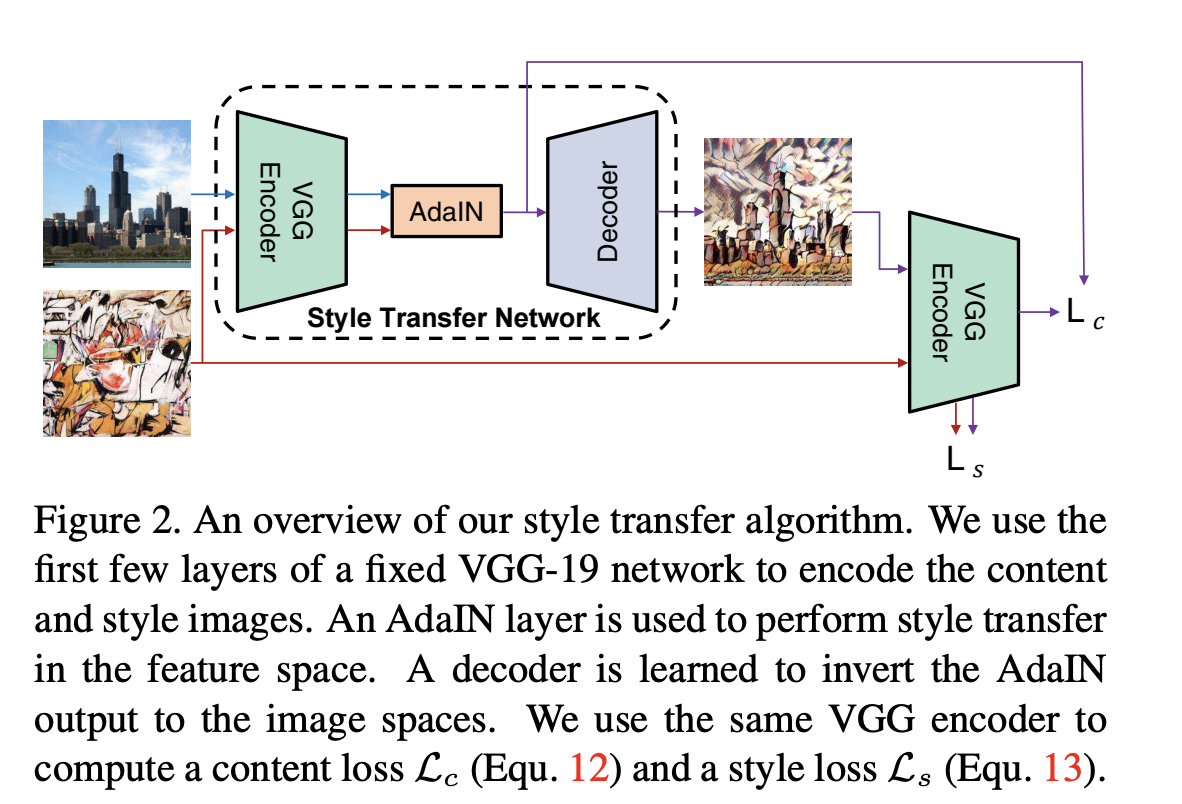
上图两个Encoder均为pre-trained VGG19, 训练过程中参数不再更新。Training和Inference过程中,Content和Style image同时传入Encoder, 得到两组feature map, 然后通过AdaIN,对content image进行变换, 转换所用的参数由计算得到,然后再传给decoder生成最终图片。
需要注意的是 Content loss和之前paper定义的有所不同,如图所示,用的是经过AdaIN变换过的feature map计算L2 loss,而非encoder的输出
小结
关于风格和内容的区分:
- 高层特征的表达的是内容
- 低维特征的Gram的矩阵表示风格
- 采用IN之后,mean 和 variance 表示风格
风格迁移网络的进化:
- 基于优化的方式,从白噪声出发,直接从内容图片、风格图片优化得到目标图片
- 将内容重构、单个风格作为模型的任务,进行训练优化,单次inference得到目标图片
- 将内容重构、风格模型进行分离,内容部分是一个Encoder-Decoder结构,风格部分保存在另一部分权重里
- 将风格部分也做成一个Encoder-Decoder结构,通过参数控制不同风格;然后进入内容部分的Decoder里
- 直接对特征进行变化,将内容特征的mean和variance转变为风格图片的值,进行重构即可
代码及效果尝试(TODO)
参考文档
- Style Transfer 风格迁移综述
- Texture Synthesis Using Convolutional Neural Networks
- Instance Normalization:The Missing Ingredient for Fast Stylization
- Image Style Transfer Using Convolutional Neural Networks
- Perceptual Losses for Real-Time Style Transfer and Super-Resolution
- StyleBank: An Explicit Representation for Neural Image Style Transfer
- A Learned Representation for Artistic Style
- Exploring the Structure of a Real-time, Arbitrary Neural Artistic Stylization Network
- Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization github