疑惑现象
对于给定的一个字符串,只保留中文、英文、数字,其他特殊符号和标点、空格都要去掉。该怎么做呢?
很直观的一个想法就是用正则来解决,比如如下代码:
std::string normalize(const std::string& input) {
std::regex pattern1("[^a-zA-Z0-9\u2e80-\u2fd5\u3190-\u319f\u3400-\u4dbf\u4e00-\u9fcc\uf900-\ufaad]");
std::string charset_range_fmt = regex_replace(input,
pattern1,
"",
std::regex_constants::match_default);
return charset_range_fmt;
}
然而,事实证明,我们想的太简单了,跑了几个例子,输入和输出如下所示:
表哥❗️~10月10破记录刘二狗【 ==normalize== 表哥❗️10月10破记录刘二狗【
美女,,,。。否 ==normalize== 美女,。。否
-\`ajfaf/-_~` ==normalize== ajfaf
看起来有些字符确实被去掉了,但有些没有,这究竟是为什么呢?是因为没去掉的字符在给出的范围内吗?并不是, 通过工具,可以看到❗对应的编码是’\u2757’,理应被我们的正则去掉的。那是什么原因呢?
解决方案
想一下正则的原理,本质上还是使用动态规划去按字符比较,而C++中,std::string的每个元素都是char, 而unicode编码需要使用多个字节来进行表示,会导致字节粒度的匹配有些问题。
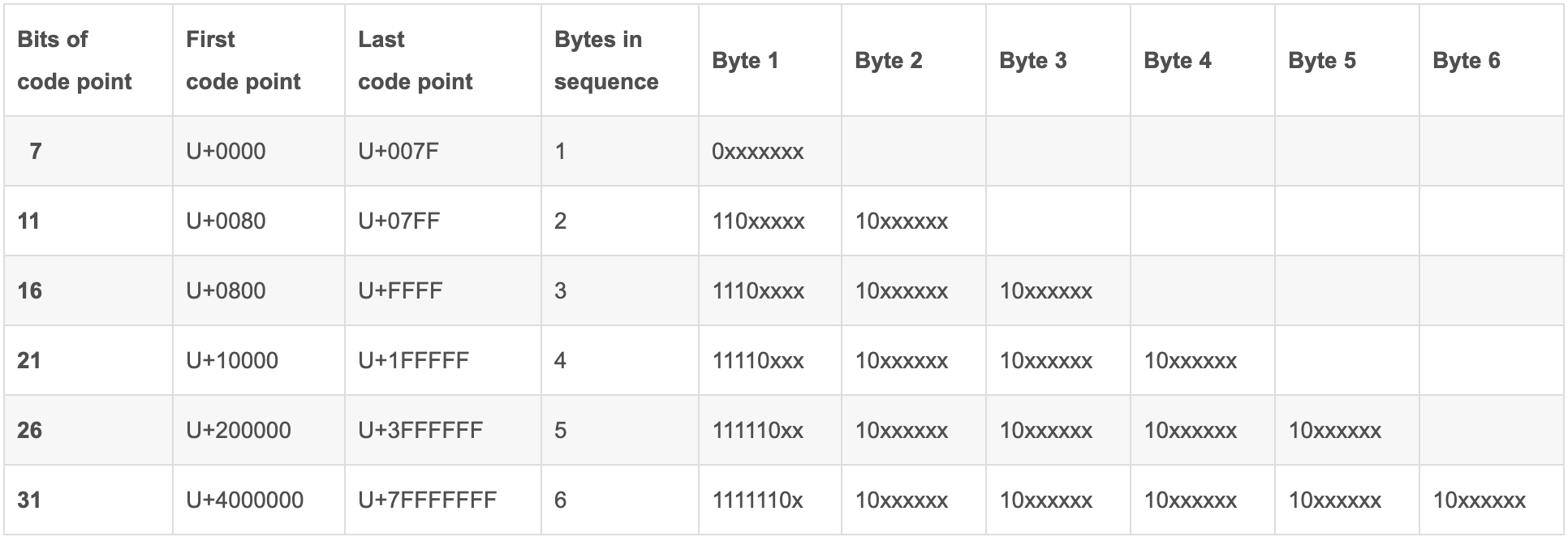
如果单独的字符和前后能够满足正则匹配的话,也不会被去掉。具体分析如下:
而为了解决这个问题,需要用到wstring,在wstring里面,基本元素是wchar_t,用于表示中文。
std::wstring wnormalize(const std::wstring input) {
std::wregex pattern1(L"[^a-zA-Z0-9\u2e80-\u2fd5\u3190-\u319f\u3400-\u4dbf\u4e00-\u9fcc\uf900-\ufaad]");
std::wstring target = L"";
std::wstring charset_range_fmt = regex_replace(input,
pattern1,
target,
std::regex_constants::match_default);
return charset_range_fmt;
}
为了使用wnormalize,还需要将string转换为wstring,可以用如下代码完成两者的相互转换:
#include <locale>
#include <codecvt>
std::wstring_convert<std::codecvt_utf8_utf16<wchar_t>> converter;
std::wstring witem = converter.from_bytes(items[i]);
converter.to_bytes(wnormalize(witem))
Reference
- https://www.cnblogs.com/zizifn/p/4716712.html