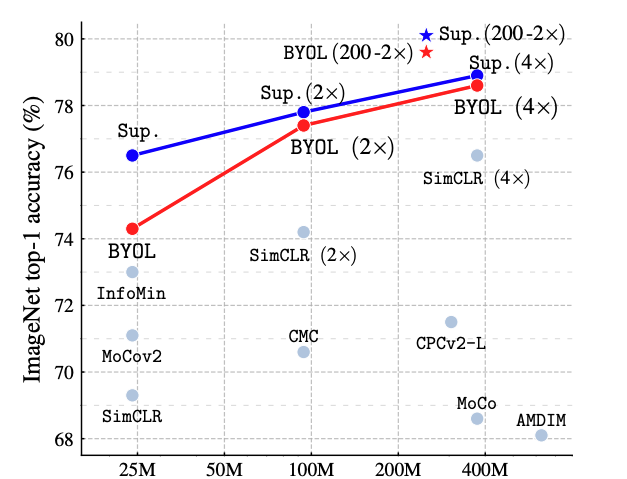
综述
在监督学习中,系统会给定一个输入x和一个标签y,来使模型输出正确的标签,而最后一层的embedding也可以用在其他任务上。 而自监督学习中,标签y并未给定,那就需要想办法来找到一个标签。
按照找到的标签来说,自监督学习可以分为两类:
-
生成式:这类方法主要关注像素的重建误差,大多数以像素的loss为主。包括AutoEncoder, VAE, GAN等。 对编码器的基本和要求是尽可能保留原始数据的重要信息,如果能够通过decoder解码回原始图片,说明 latent code重建的足够好了。
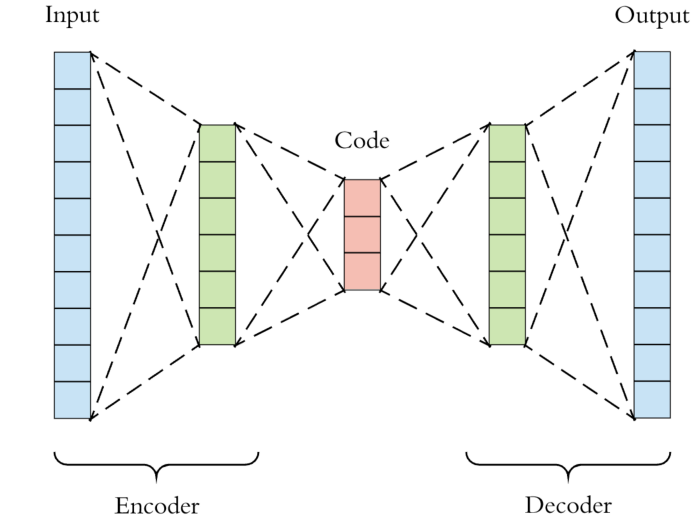
但是,这种方法有一个问题:
- 进行像素重建的计算开销非常大
- GAN的方式会是任务变得复杂而且难以优化
在这篇博客中,有一个很好地例子。 对于一张钱币,我们能够很容易地分辨真假,说明在识别真假这个任务里,我们的特征已经学习的很好了;但是,画一张同样的纸币出来,几乎是不可能的。 这个例子告诉我们,重建是好特征表达的充分条件,但不是必要条件。就有了判别式的方法。


-
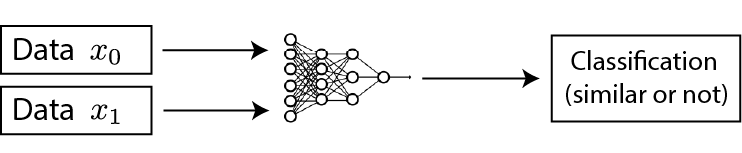
判别式:这类方法并不要求模型能够重建原始输入,而是希望模型能够在特征空间上对不同的输入进行分辨,就像上面美元的例子。
这类方法有以下特点:
- 在 feature space 上构建距离度量;
- 通过特征不变性,可以得到多种预测结果;
- 使用 Siamese Network;
- 不需要 pixel-level 重建。
而这类方法的主要任务,就是如何构造正样本和负样本。
两类方法的结构如下所示:
Contrastive Based
从前面我们知道,由一个原始的 input 去建模一个 high-level representation 是很难的,这也是自监督学习想做的事情。 其中常用的策略是:future,missing 和 contextual,即预测未来的信息, 比如 video 中当前帧预测后面的帧;丢失的信息或者是上下文的信息, 比如 NLP 里面的 word2vec 和 BERT。
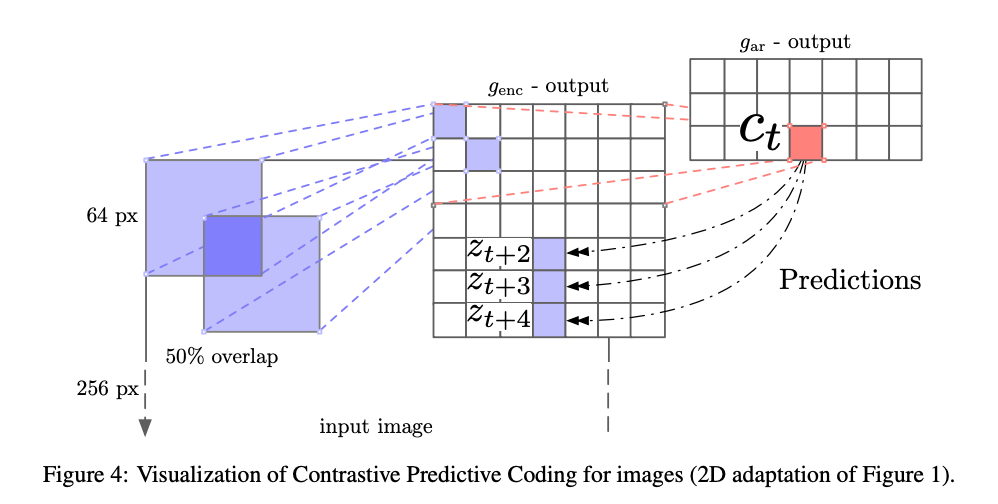
Contrastive Predictive Coding
这篇文章主要是通过 contrastive 的方式在 speech, images, text 和 在reinforcement learning 中都取得了很好的效果。
对于语音和文本,可以充分利用了不同的 k 时间步长,来采集正样本,而负样本可以从序列随机取样来得到。
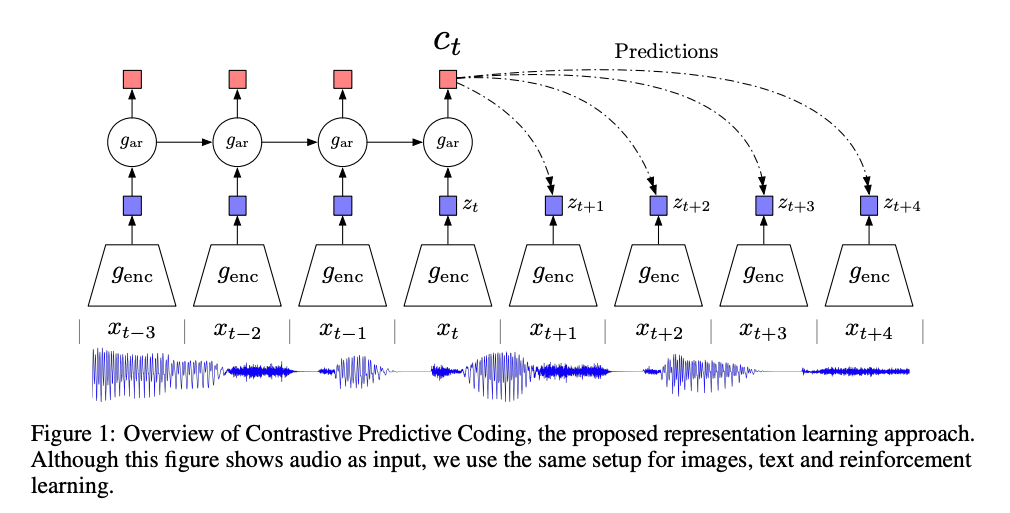
对于图像任务,可以使用 pixelCNN 的方式将其转化成一个序列类型,用前几个 patch 作为输入,预测下一个 patch。
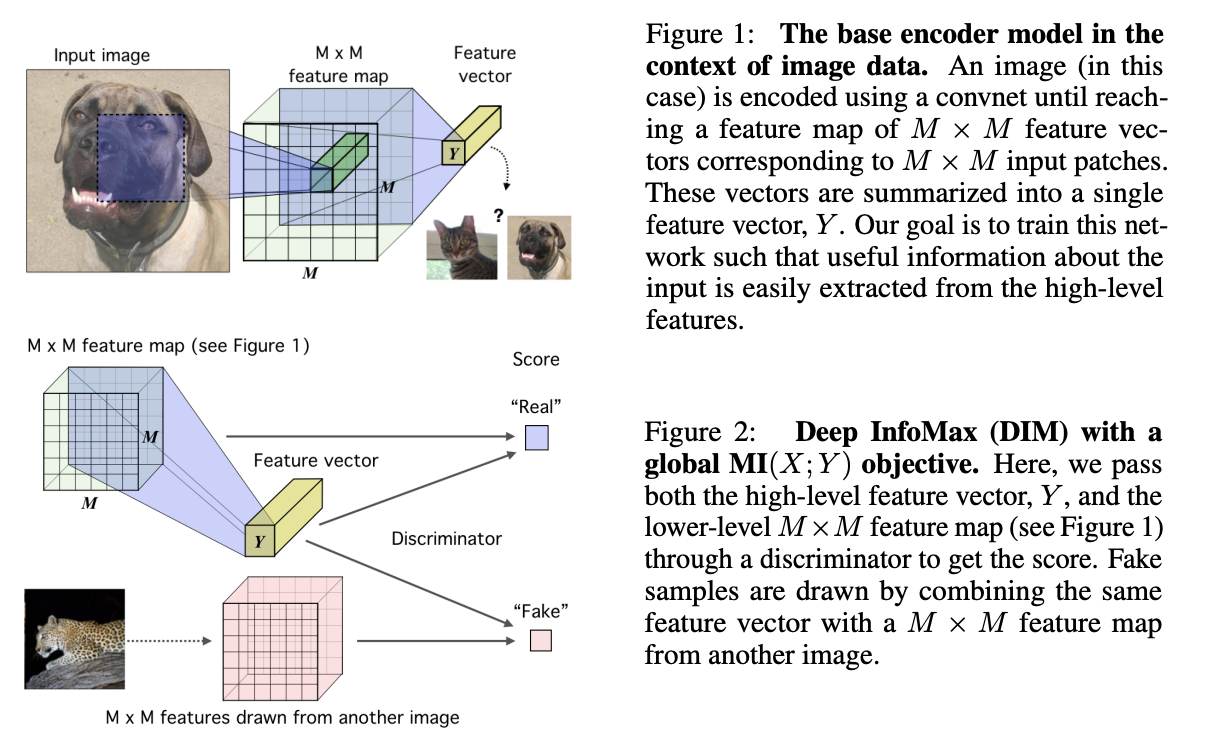
Deep InfoMax
和CPC不同,Deep InfoMax并没有对图像进行patch,而是在feature维度上进行的操作:
对global_feature和local_feature进行了判别,
正样本是图片的global feature和中间某个feature map的m*m个local feature,负样本是其他图片的local feature。
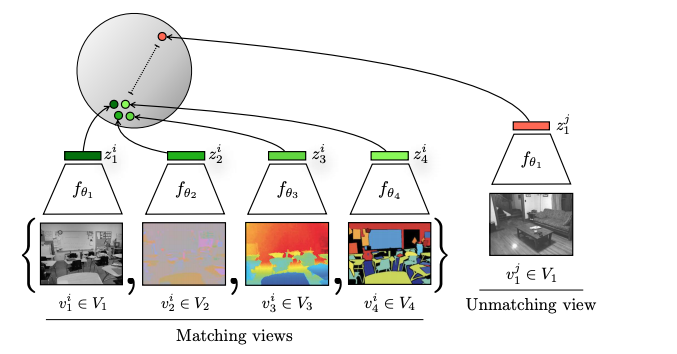
Contrastive MultiView Coding
CMC这篇论文充分利用了各个通道的信息,比如同一张图片的 RGB图 和 深度图。
而且通过这个方式,每个 anchor 不仅仅只有一个正样本,可以通过多模态得到多个正样本。
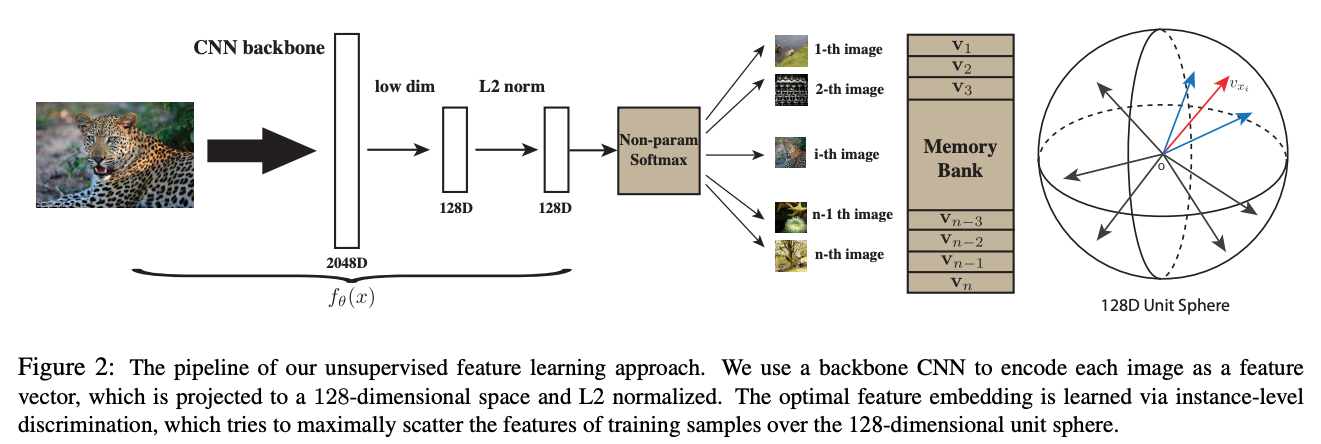
Memory Bank
我们可以发现,在上述过程中,负样本的数量有很多,但是一个batch获取到的负样本总是有限的,
怎么利用大量的负样本呢?把计算过的特征存起来,下次直接使用不就可以了吗?
Memory Bank应运而生,把之前模型产生样本特征全部存起来,
当前计算损失的时候直接拿来用就可以了,每次模型更新完后将当前的特征重新更新到 memory bank 中,
以便下一次使用。这个工作的缺点就在于每次需要将所有样本的特征全部存起来。
后续 kaiming 大神提出的 Moco[28],
主要的贡献是 Momentum Update、 shuffleBN 等技术点来优化这个过程。
MOCO
首先,从NLP的无监督例如BERT出发 ,作者指出Computer Vision的无监督学习需要建立dictionary: 因为数据信号是连续的,分布在空间高维,并且不像NLP那样结构化。 将现有的无监督方法归类为dictionary learning之后, 作者提出建立dictionary依赖两个必要条件:
- large,dictionary的大小需要足够大,才能对高维、连续空间进行很好的表达;
- consistent,dictionary的key需要使用相同或者相似的encoder进行编码, 这样query和key之间的距离度量才能够一致并且有意义。
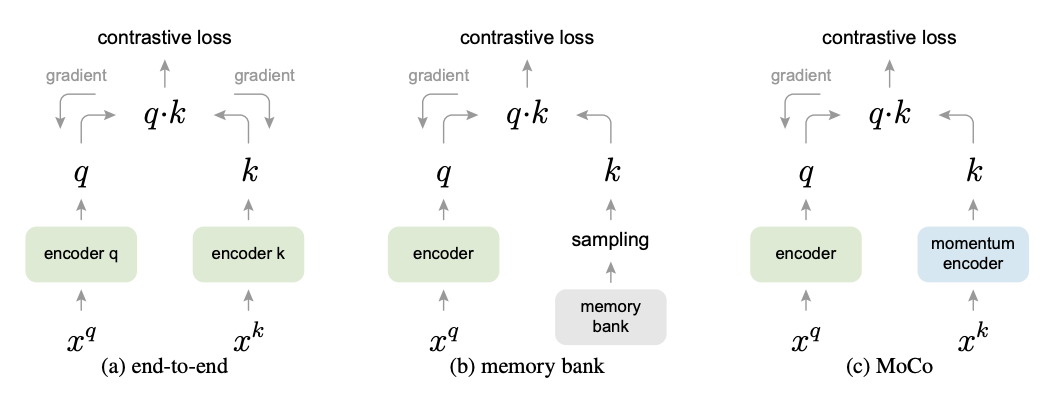 如图,large这个条件是通过一个先进先出队列实现,
consistent这个条件通过momentum更新的encoder来实现,
类似于DL里面常用的exponential decay技巧。
如图,large这个条件是通过一个先进先出队列实现,
consistent这个条件通过momentum更新的encoder来实现,
类似于DL里面常用的exponential decay技巧。
下图给出了伪代码

SimCLR
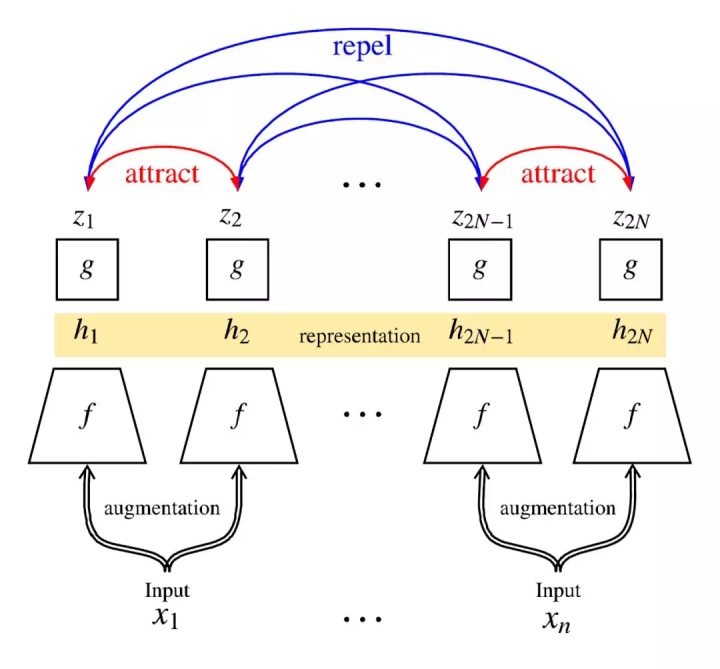
随机采样一个batch; 对batch里每张图像做两种增强,可以认为是两个view; 让同一张图的不同view在latent space里靠近,不同图的view在latent space里远离, 通过NT-Xent实现。

这样的话,可以通过增加batch size来增加负样本数量,更利于多机扩展。
BYOL
上述方案都需要负样本,BYOL则使用了另一种方式避开了负样本的存在。 直接去拉近正样本对之间的特征距离。
论文基于这样一个发现: 两个随机初始化的网络A和B,输入同一个样本的不同augmentation版本,A的输出特征作为B的监督信息, A的参数固定不动,B训练,训练到最后B的特征表达能力竟然青出于蓝,比A还要好, 那如果再弄第三个网络C去跟B学,第四个网络D跟C学, 就可以像梯云纵那样,左脚踩右脚,螺旋升天,法力无边。 相比之下,后面用moving average / mean teacher的具体实现, 只不过是把上述交替学习的过程变得小步快跑,更为高效而已,并不是最核心的贡献了。
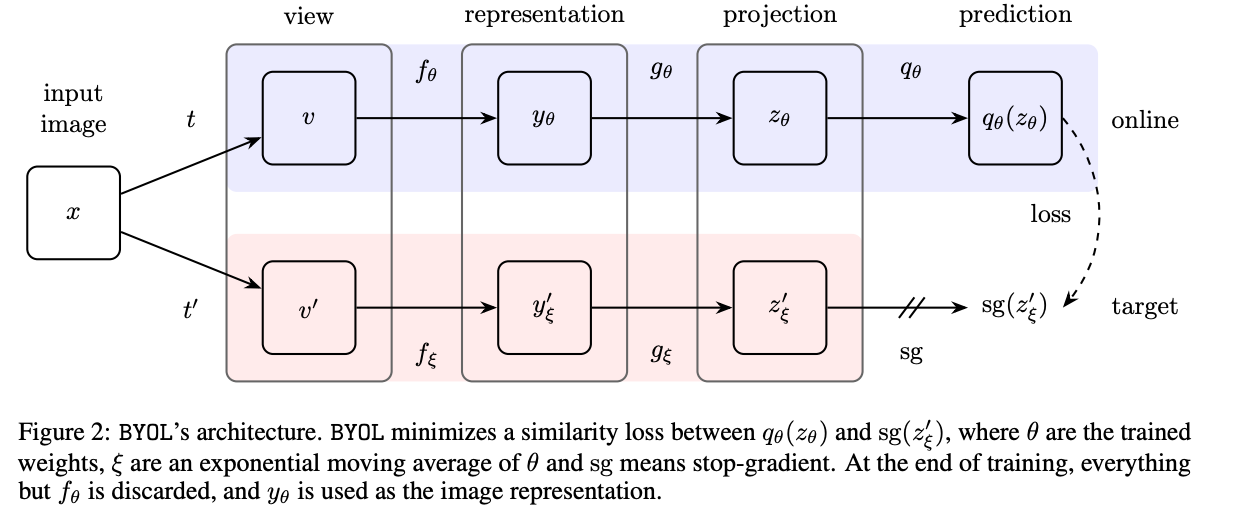
contrastive learning框架有两大目标:
- 不同的原样本有不同的表征,负样本的存在就是为了确保这个目标
- 同一个原样本的不同augmentation结果 / view有相同的表征
之前其实已经有挺多工作告诉我们,一个随机初始化的CNN就已经具备一定程度的图像特征抽取能力。 更进一步地,如果CNN随机初始化之后,就已经会把不同的样本输入投射到特征空间的不同地方, 并且投射得足够分散,那它就已经完成了contrastive learning框架中第一个目标。 如果上述猜测成立,那么只要在接下来的训练过程中达成contrastive learning框架第二个目标, 并且小心翼翼地维护第一个目标不被破坏,避免网络收敛到trivial solution, 那就确实可以抛开负样本。 而这个小心翼翼维护的操作,在BYOL里面就体现为”teacher不要太快跟上student的步伐“, 论文Table 5说明,跟得太快会破坏contrastive特性,跟得太慢又有损训练效率, 为了trade-off,就祭出了mean teacher这个好用的工具,平衡稳定性与效率。
参考文献
- https://zhuanlan.zhihu.com/p/108625273
- Comprehensive Introduction to Autoencoders
- Contrastive Self-Supervised Learning
- https://www.zhihu.com/question/402452508/answer/1293771636
- How Useful is Self-Supervised Pretraining for Visual Tasks定义了 Utility 来衡量 SSL 方法的效率,测试了众多 SSL 方法在各种任务下不同的有效性 。
- Rethinking Image Mixture for Unsupervised Visual Representation Learning 对比学习里的 Mixup
- Big Self-Supervised Models are Strong Semi-Supervised LearnersSimCLR作者的新作,大力出奇迹。
- Bootstrap Your Own Latent A New Approach to Self-Supervised Learning不需要制造负样本,model 之间互相迭代 teaching 就可以得到很好的 performance。
- What Makes for Good Views for Contrastive Learning
- https://www.zhihu.com/question/402452508/answer/1294166177
- Contrastive Predictive Coding