对于从事深度学习的人来说,tf.nn.embedding_lookup这个函数应该并不罕见,活跃在各种embedding领域-文本、用户等。
然而今天,一个小伙伴在把checkpoint导出为pb的时候,遇到了如下错误:
ValueError: Cannot create a tensor proto whose content is larger than 2GB.
错误表达的很明确,转换成pb格式的时候,单个proto 不能大于2G,可是怎么去解决呢?
embedding_lookup的分区
拿这个错误去搜索了一下,发现embedding_lookup可以从多个变量里去获取查询,这样的话, 可以把一个很大的查询表拆分成若干个小的表,就可以转换成pb了。
下面的代码给出了使用的例子和输出结果:
per_shard_nums = 10
# 10 * 1
weights = []
for i in range(100):
emb = tf.get_variable(
'words-%02d' % i,
initializer=tf.constant(
# np.reshape(np.arange(i * per_shard_nums, i * per_shard_nums + per_shard_nums), (-1, 1))
np.arange(i * per_shard_nums, i * per_shard_nums + per_shard_nums)
)
)
weights.append(emb)
idx = tf.placeholder(tf.int64, shape=[None])
embedding = tf.nn.embedding_lookup(weights, idx, partition_strategy='mod')
embedding_2 = tf.nn.embedding_lookup(weights, idx, partition_strategy='div')
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
# print(sess.run(weights))
print(sess.run(embedding, feed_dict={idx: [0, 1, 2, 99, 999, 100]}))
# res: [ 0 10 20 990 999 1]
print(sess.run(embedding_2, feed_dict={idx: [0, 1, 2, 99, 999, 100]}))
# res: [ 0 1 2 99 999 100]
我们构造了这样一个例子:有1000个id,每个id对应的值是自身;将这1000个值放到100个variable里面,使用embedding_lookup进行查询。
细心的同学可能已经发现了,有一个参数叫做partition_strategy,这个是用来干什么的呢,有什么区别呢?
按照如上方式构造查询表之后,查询表的大小可以视为[num_shards, per_shard_num, embedding_len],而partition_strategy决定的,就是确定分区和每个分区内index的方式。
假设要查询的编号为index,
那么’mod’对应的分区和行号为:line, shard = divmod(index, num_shard),
而’div’模式对应的分区和行号为shard, line = divmod(index, per_shard_num)。
回到代码中的例子,num_shards=100, per_shard_num=10, 对于99这个序号,
‘mod`模式计算如下:
line, shard = divmod(99, 100) = (99, 0), val = 990
div模式计算如下:
line, shard = divmod(99, 10) = (9, 9), val = 99
其他的类似可得。
PartitionedVariable与partitioner
查看函数的注释,可以发现如下内容:
partitioner.
If `len(params) > 1`, each element `id` of `ids` is partitioned between
the elements of `params` according to the `partition_strategy`.
In all strategies, if the id space does not evenly divide the number of
partitions, each of the first `(max_id + 1) % len(params)` partitions will
be assigned one more id.
If `partition_strategy` is `"mod"`, we assign each id to partition
`p = id % len(params)`. For instance,
13 ids are split across 5 partitions as:
`[[0, 5, 10], [1, 6, 11], [2, 7, 12], [3, 8], [4, 9]]`
If `partition_strategy` is `"div"`, we assign ids to partitions in a
contiguous manner. In this case, 13 ids are split across 5 partitions as:
`[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10], [11, 12]]`
注释帮助我们更形象地理解了partition的作用,但是第一段话也给我带来了疑问:
id space实际上是人为指定的,为什么要指定一个不能整除的最大值呢?在权重初始化的时候也不方便啊,
除非有某个函数,可以指定总数和分区数?那就是tf.get_variable这个函数了,看一下它的参数,果然有partitioner这个参数,
一路追踪进去,看到了如下注释:
If a partitioner is provided, a `PartitionedVariable` is returned.
Accessing this object as a `Tensor` returns the shards concatenated along
the partition axis.
Some useful partitioners are available. See, e.g.,
`variable_axis_size_partitioner` and `min_max_variable_partitioner`.
partitioner: Optional callable that accepts a fully defined `TensorShape`
and `dtype` of the Variable to be created, and returns a list of
partitions for each axis (currently only one axis can be partitioned).
The `partitioner` must be a callable that accepts a fully defined
`TensorShape` and returns a sequence of integers (the `partitions`).
These integers describe how to partition the given sharded `Variable`
along the given dimension. That is, `partitions[1] = 3` means split
the `Variable` into 3 shards along dimension 1. Currently, sharding along
only one axis is supported.
If the list of variables with the given name (prefix) is already stored,
we return the stored variables. Otherwise, we create a new one.
If initializer is `None` (the default), the default initializer passed in
the constructor is used. If that one is `None` too, we use a new
`glorot_uniform_initializer`. If initializer is a Tensor, we use
it as a value and derive the shape from the initializer.
If the initializer is a callable, then it will be called for each
shard. Otherwise the initializer should match the shape of the entire
sharded Variable, and it will be sliced accordingly for each shard.
Some useful partitioners are available. See, e.g.,
`variable_axis_size_partitioner` and `min_max_variable_partitioner`.
还是云里雾里的,不如直接用代码来说话吧:
partitioner = tf.fixed_size_partitioner(100, axis=0)
with tf.variable_scope("embedding", partitioner=partitioner):
weights = tf.get_variable(
"weights",
[1000],
initializer=np.arange(1000),
partitioner=partitioner
)
idx = tf.placeholder(tf.int64, shape=[None])
embedding = tf.nn.embedding_lookup(weights, idx, partition_strategy='mod')
embedding_2 = tf.nn.embedding_lookup(weights, idx, partition_strategy='div')
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
# print(sess.run(weights))
print(sess.run(embedding, feed_dict={idx: [0, 1, 2, 99, 999, 100]}))
# res: [ 0. 10. 20. 990. 999. 1.]
print(sess.run(embedding_2, feed_dict={idx: [0, 1, 2, 99, 999, 100]}))
# res: [ 0. 1. 2. 99. 999. 100.]
可以发现,这段代码实现了和第一段代码一样的功能,使用的都是tf自带的函数。
其中,tf.fixed_size_partitioner可以将参数在指定维度(axis)分割成指定份数(num_shards),
要想使用该接口,需要搭配tf.variable_scope才行,
值得注意的是,这样得到的weights是一个PartitionedVariable类型的变量,不能直接通过sess.run()获取到。
那么,对参数进行切分有什么用处呢?可以解决开始提到的单个variable过大问题。如果只是为了解决这个问题,是不是有些大材小用了呢?
其实,这个设计是为了更高效的进行分布式训练,考虑这样一个场景: 在tensorflow的ps架构中,ps负责存储模型的参数,worker负责使用训练数据对参数进行更新。 默认情况下,tensorflow会把参数按照round-robin的方式放到各个参数服务器(ps)上。 例如,模型有5个参数(注意这五个参数都是tensor而非标量),P1,P2, P3, P4, P5,由2个ps(记为ps0和ps1)负责存放, 则P1,P3,P5会存放在ps0上,P2,P4会存放在ps1上。 显然,如果P1,P3,P5都比P2,P4大,那ps0上存放的参数会远大于ps1。 这样在更新参数时,ps0的网络就有可能成为瓶颈。
造成参数分布不均匀的主要原因在于tensorflow在为各个参数分配ps时,只是在参数这个粒度做的,粒度太大。 如,参数A的大小为10241024,参数B的大小为22。 在这种情况下,如果不对A和B进行分割,无论如何分配都无法做到均匀。 如果把A和B分割成5121024 + 5121024和12 + 12,那在两台ps上就可以均匀分配。
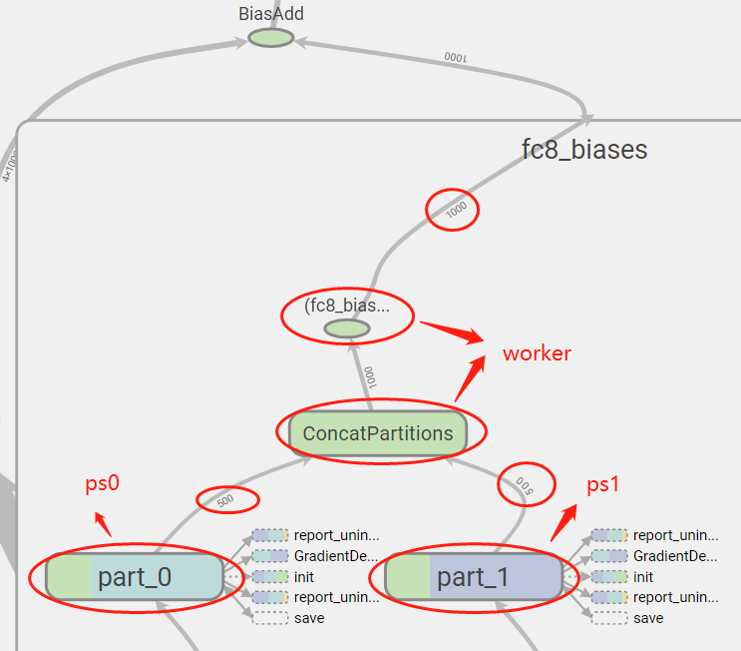
tensorboard效果如下所示:
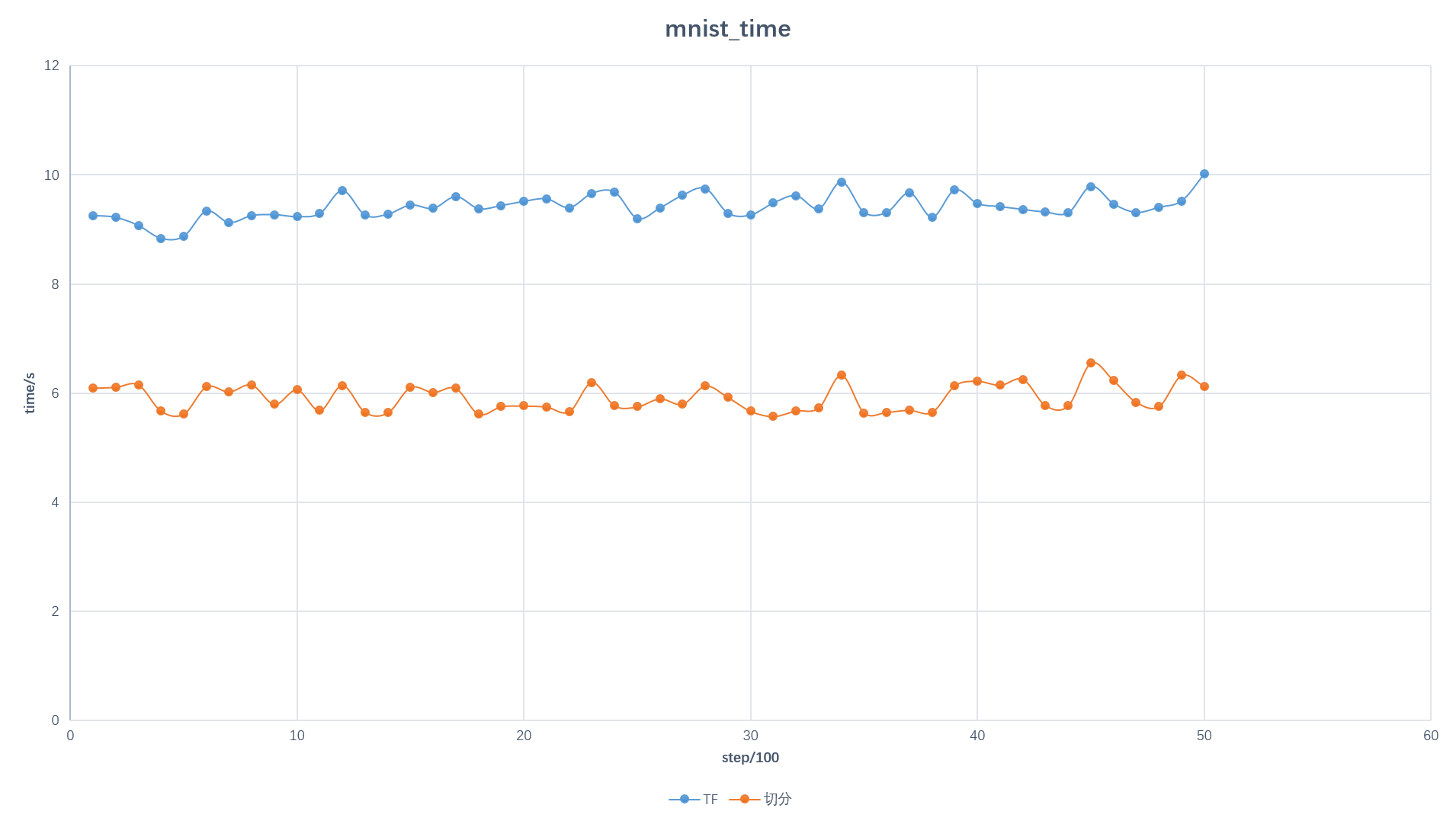
训练时长对比:
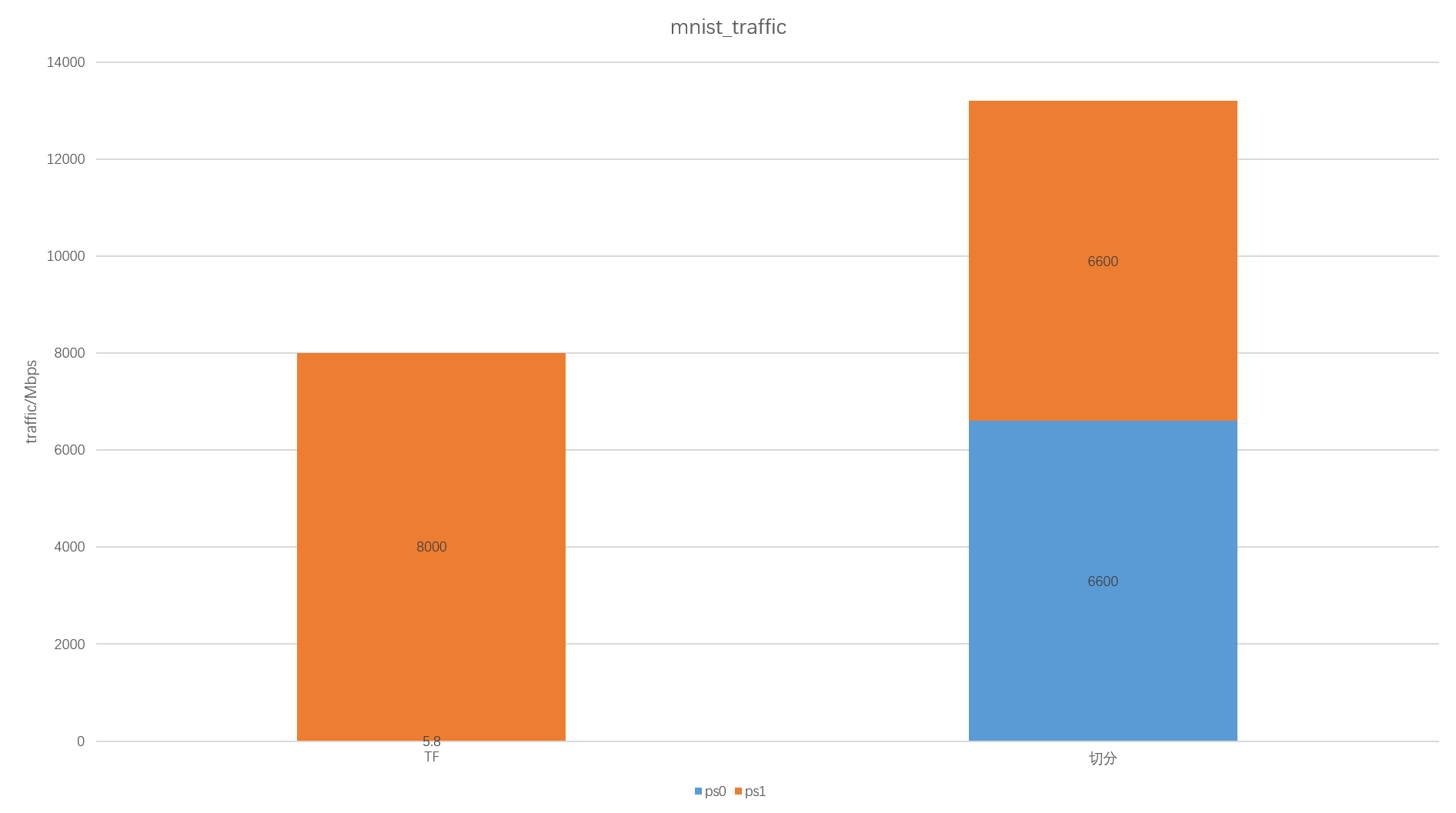
ps流量对比:
本文代码地址
链接。
参考
- https://www.cnblogs.com/gongxijun/p/9995960.html
- https://www.jianshu.com/p/abea0d9d2436
- https://blog.csdn.net/u013431916/article/details/80330813