深度学习里,图像的读取和预处理是必不可少的操作,而tensorflow也很应景地提供了很多方便的函数,比如
tf.image.decode_image, tf.image.resize_images等等。然而,实际调用模型的时候呢,一般会采用
opencv或者pillow来对图片进行操作。这里面会有一些较为隐蔽的坑,下面就一一道来。
读取图片
tf.image.decode_jpeg, cv2.imread, Image.open都提供了读取jpeg图片的功能,然而它们之间还是有些不同的。
首先看一下用法吧:
raw_data = tf.read_file(image_path)
tf_image = tf.image.decode_jpeg(raw_data, channels=3)
#tf_image = tf.image.decode_jpeg(raw_data, channels=3, dct_method="INTEGER_ACCURATE")
cv_image = cv2.imread(image_path)
cv_rgb = cv_image[:, :, ::-1]
pil_image = Image.open(image_path)
pil_mat = np.array(pil_image)
当我们测试得到的结果是不是一致的时候,会让我们很疑惑: 三者各不相同,基于文档,tf和pillow读取的图片都是RGB格式的,而OpenCV得到的是BGR格式,因此需要转换一下。 可是转换了之后,还是两两不同,原因在哪里呢? 先来看一下tf的函数说明:
tf.io.decode_jpeg(
contents,
channels=0,
ratio=1,
fancy_upscaling=True,
try_recover_truncated=False,
acceptable_fraction=1,
dct_method='',
name=None
)
# dct_method: An optional string.
# Defaults to "". string specifying a hint about the algorithm used for decompression.
# Defaults to "" which maps to a system-specific default.
# Currently valid values are ["INTEGER_FAST", "INTEGER_ACCURATE"].
# The hint may be ignored (e.g., the internal jpeg library changes to a version
that does not have that specific option.)
而源文件里
明确指出,默认方式是"INTEGER_FAST",会不会是模式的选择不同导致结果不同呢?
指定dct_method="INTEGER_ACCURATE",发现OpenCV和tf的表现一致了。但是pillow的结果和两者都不一样。
这个讨论 中有一句话貌似揭示了答案:它们用的库不一样。
First time i hear that. Very interesting! scipy seems to use libjpeg-dev (through PIL/Pillow), while tensorflow might use libjpeg-turbo. – sascha Jul 19 ‘17 at 21:27
为了验证这一点,通过查看编译信息验证:
import cv2
print(cv2.getBuildInformation())
发现输出有这样一行,
3rdparty dependencies: ittnotify libprotobuf libjpeg-turbo libwebp libpng libtiff libjasper IlmImf quirc zlib ippiw ippicv
而cv2.imread()的注释里也提到一点,使用的jpeg库是和系统相关的。
那么,pillow使用的是什么库呢?
# for linux
# ldd /Users/zhangchao/anaconda3/envs/dl/lib/python3.6/site-packages/PIL/_imaging.so
# for mac
otool -L /Users/zhangchao/anaconda3/envs/dl/lib/python3.6/site-packages/PIL/_imaging.cpython-36m-darwin.so
/Users/zhangchao/anaconda3/envs/dl/lib/python3.6/site-packages/PIL/_imaging.cpython-36m-darwin.so:
@loader_path/.dylibs/libjpeg.9.dylib (compatibility version 13.0.0, current version 13.0.0)
@loader_path/.dylibs/libopenjp2.2.1.0.dylib (compatibility version 7.0.0, current version 2.1.0)
@loader_path/.dylibs/libz.1.2.11.dylib (compatibility version 1.0.0, current version 1.2.11)
@loader_path/.dylibs/libtiff.5.dylib (compatibility version 10.0.0, current version 10.0.0)
/usr/lib/libSystem.B.dylib (compatibility version 1.0.0, current version 1252.0.0)
两者确实不一样。
图片解码的坑总结如下:
- libjpeg不同版本之间有差异
- opencv使用的libjpeg和系统相关,本机是libjpeg-turbo
- pillow使用的是libjpeg-dev
- tensorflow使用的是libjpeg-turbo(不确信,不过貌似只有turbo支持不同模式)
- decode_jpeg默认为fast
缩放图片
tf.image.resize_images(), cv2.resize()
这个主要是看到了这篇博客 的吐槽,验证了一下,发现每个像素值确实是有差别的,为了防止这个差距影响模型的准确度,就把用到的tf.image都通过tf.py_wrapper重新写了一遍方便自己使用。
今天无意间又看到了类似的问题,发现官方还是没有解决,上次没有探究原理,今天就深入了解一下原因吧。
对比了OpenCV和tf的源码,发现它们之间的区别在于: tensorlfow将1个像素的值视为点,没有面积;而OpenCV将1个像素视为1*1的区域,区域的中心为0.5,0.5。 从而导致计算插值系数的时候,得到的结果不一样。感觉还是opencv的更加符合视觉效果,但是TensorFlow一直没有改动,甚至没有加一个可选项……简直无语了
线性插值与双线性插值
-
线性插值:
已知数据 \((x_0, y_0)\) 与 \((x_1, y_1)\),要计算 \([x_0, x_1]\) 区间内某一位置 x 在直线上的y值:
\[\frac{y - y_0}{x -x_0} = \frac{y_1 - y_0}{x_1 - x_0}\] \[y = y_0 + (x -x_0)\frac{y_1 - y_0}{x_1 - x_0}\] -
双线性插值
双线性插值是有两个变量的插值函数的线性插值扩展,其核心思想是在两个方向分别进行一次线性插值。 如下图所示,已知\(Q_{11},Q_{12},Q_{21},Q_{22}\)的值,先进行线性插值,得到\(R1,R2\)的值,进而得到P的值。
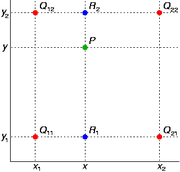
-
图像里的双线性插值
如果直接按照上述方式进行图像缩放的话,得到的结果会很奇怪。 主要原因在于,上述方式为数学表达,认为点没有面积。 而在图像中,一个像素是有面积的,和4个点关联。 我们说\([0,0]\)这个像素的值为127,画在坐标系里。 其实是说\([0,0],[0,1],[1,0],[1,1]\)这个以\([0.5,0.5]\)为中心,边长是1的正方形内的值都是127。 因此,可以认为这个正方形的中心值决定了这个像素的值,也就是OpenCV的处理方式。 具体请看下图:
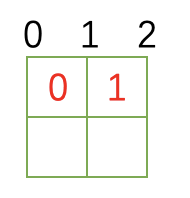
python simulation
下面给出了python版本的实现,来说明原理。完整代码请参考这这里
def compute_interpolation_weights(out_size, in_size, scale):
"""
calculate interpolation in tensorflow
:param out_size:
:param in_size:
:param scale:
:return:
"""
# lower, upper, lerp
res = [[0, 0, 0] for _ in range(out_size + 1)]
for i in range(out_size - 1, -1, -1):
val = i * scale
res[i][0] = int(val)
res[i][1] = min(res[i][0] + 1, in_size - 1)
res[i][2] = val - int(val)
return res
def cv_compute_interpolation_weights(out_size, in_size, scale):
"""
calculate interpolation in opencv
:param out_size:
:param in_size:
:param scale:
:return:
"""
# lower, upper, lerp
res = [[0, 0, 0] for _ in range(out_size + 1)]
res[-1] = [0, 0]
for i in range(out_size - 1, -1, -1):
val = (i + 0.5) * scale - 0.5
res[i][0] = max(0, int(val))
res[i][1] = min(res[i][0] + 1, in_size - 1)
res[i][2] = max(0, val - int(val))
return res
参考
- https://github.com/tensorflow/tensorflow/issues/6720
- https://hackernoon.com/how-tensorflows-tf-image-resize-stole-60-days-of-my-life-aba5eb093f35
- https://github.com/opencv/opencv/blob/master/modules/imgproc/src/resize.cpp
- https://github.com/tensorflow/tensorflow/blob/e073322452e41e76754314aa75d543d071003fc5/tensorflow/core/kernels/resize_bilinear_op.cc